
Kafka Is Not Your Data Lake
When teams start building large-scale distributed systems, one pattern appears again and again:
"We already have Kafka. Let's just use it for everything."
It sounds efficient.
It feels modern.
It is almost always wrong.
In event-driven architectures (like Digital Twins) --- especially those generating TB-scale datasets --- confusing event streaming with bulk data storage creates scaling, governance, and replay problems later.
This article explains why separating Control Plane and Data Plane is not an optimization --- it's a foundational architectural decision.
The Reality of Digital Twin Workloads
A serious Digital Twin system does not generate just one type of data.
It typically produces:
- Continuous telemetry streams
- State updates (engine, power mode, subsystem health)
- Risk indicators and anomaly flags
- Batch exports (daily dumps, logs, raw sensor archives)
- Simulation outputs
- Historical replay scenarios
These data types behave very differently.
Yet many architectures try to push all of them through the same system.
That's where the trouble begins.
Kafka Is an Event Backbone --- Not a Data Lake
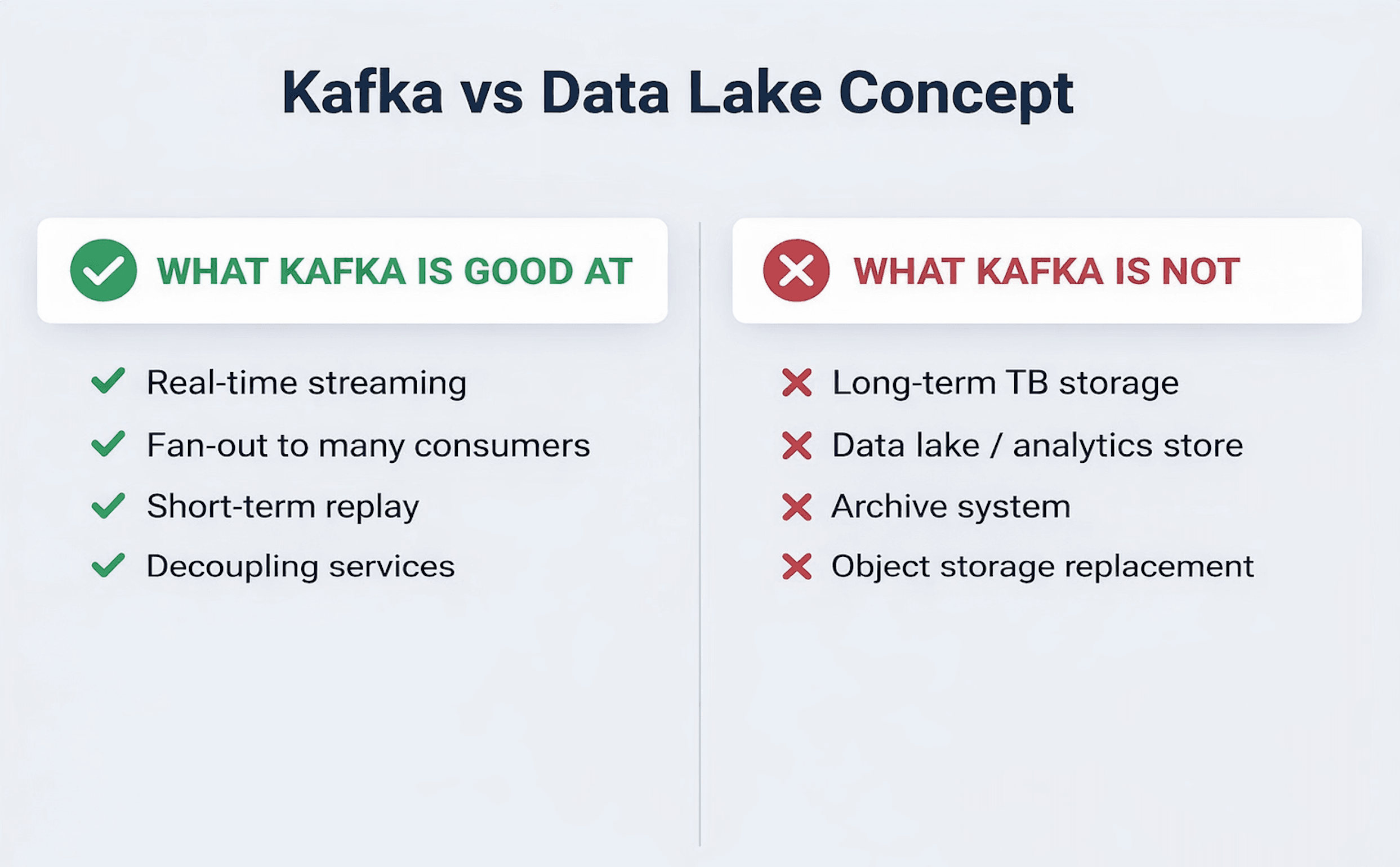
Kafka is exceptional at:
- Real-time event streaming\
- Multi-consumer fan-out\
- Replay within retention windows\
- Loose coupling between components
Kafka is not designed to:
- Store multi-terabyte raw datasets
- Act as long-term archival storage
- Serve as a data lake for bulk analytics
- Replace object storage systems
Trying to use Kafka as both event bus and data warehouse introduces:
- Retention conflicts
- Storage pressure
- Governance complexity
- Operational instability
The fix is architectural, not configurational.
Control Plane vs Data Plane
The clean design pattern is separation.
#Control Plane (Event Layer)
Handled by Kafka (or similar event streaming platform).
Carries:
- Telemetry events\
- Digital Twin state updates\
- Alerts and anomaly indicators\
- Dataset metadata notifications\
- Replay triggers
Events are small, structured, and time-sensitive.
#Data Plane (Bulk Storage Layer)
Handled by object storage (S3-compatible or cloud-managed).
Stores:
- Raw dumps\
- Log archives\
- Simulation outputs\
- Large batch exports\
- Historical datasets
These are large, durable, governed artifacts.
The Pointer Pattern
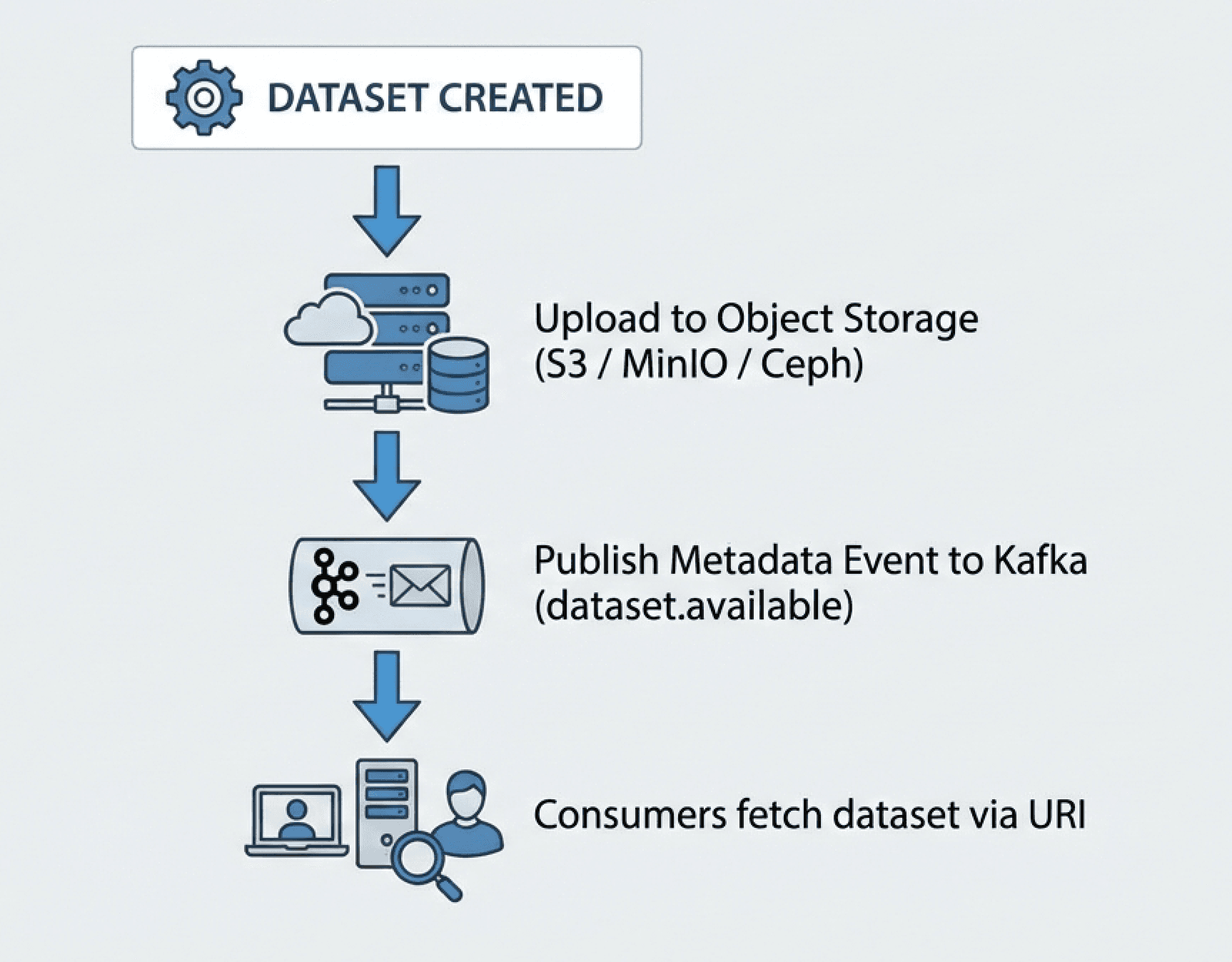
Instead of pushing large datasets through Kafka, publish metadata events that point to stored datasets.
Example:
{
"event_type": "dataset.available",
"pilot_id": "PILOT_A",
"dataset_id": "dt-2026-02-16-daily",
"object_uri": "s3://consortium/pilot_a/2026/02/16/daily_dump.parquet",
"checksum": "sha256:abc123...",
"size_bytes": 275000000000
}
Kafka carries:
- The notification\
- The schema reference\
- The governance tags
Object storage holds:
- The actual 275GB dataset
This keeps the event backbone lightweight and scalable.
Replay by Design
Replay is critical in Digital Twin systems:
- Simulation validation\
- Post-incident forensic analysis\
- Model retraining\
- Scenario testing
With proper separation:
- A dataset is uploaded to object storage.
- A metadata event is published.
- Consumers request a replay window.
- A controlled service re-injects replayed events into Kafka.
- Simulations run deterministically.
Replay becomes intentional --- not accidental.
Storage Model Matters More Than Provider
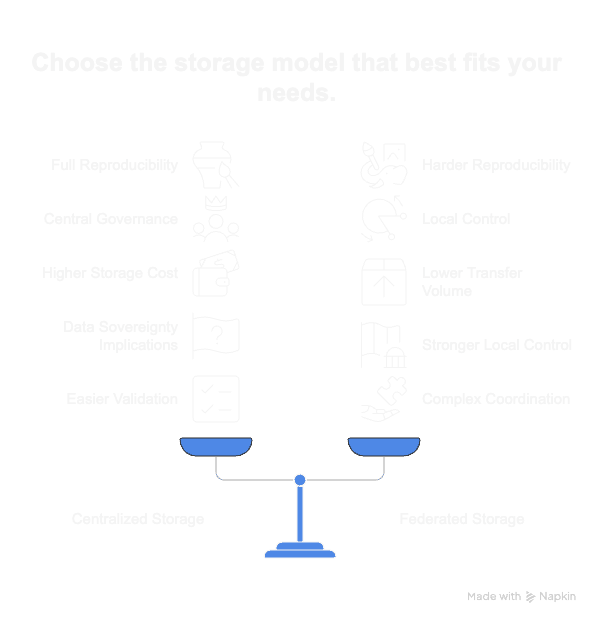
Before choosing technology, decide the model.
#Option 1 --- Centralized Consortium Storage
All pilots upload raw datasets to a shared object storage.
Pros: - Full reproducibility\
- Central governance\
- Easier validation
Cons: - Higher storage cost\
- Data sovereignty implications\
- Transfer overhead
#Option 2 --- Federated Pilot Storage
Raw data remains with each pilot.
Only curated or requested subsets are exported centrally.
Pros: - Lower transfer volume\
- Stronger local control
Cons: - Harder reproducibility\
- Replay depends on partner availability\
- More complex coordination
The architectural model influences the system more than whether you use MinIO, Ceph, S3, or Blob.
Why This Separation Is Non-Negotiable at Scale
As systems grow, three forces dominate:
- Data volume
- Governance
- Reproducibility
Without Control/Data Plane separation:
- Kafka retention becomes a liability\
- Replay becomes chaotic\
- Storage costs explode\
- Compliance becomes unclear
With separation:
- Events stay fast\
- Storage stays durable\
- Replay stays controlled\
- Governance stays explicit
The Bigger Lesson
Distributed systems fail less often from lack of technology
and more often from lack of architectural clarity.
Kafka is powerful.
Object storage is powerful.
But they solve different problems.
Confusing them creates fragility.
Separating them creates scalability.
Closing Thought
If you're building:
- Event-driven platforms\
- AI-powered digital twins\
- Real-time + historical hybrid systems
Ask yourself:
Is your event backbone doing too much?
If yes, it's time to separate control from data.
That decision will outlast any technology choice.